[Update (3/29/2007): there’s an important correction here.]
Too many projects chasing too little time means you have to prioritize (in fact, if you don’t have to prioritize, you ought to question whether you’re doing anything worthwhile at all!). I’ve been spending a lot of time lately looking at the Biblical People data in Logos Bible Software, getting ready to incorporate the work i’ve done on New Testament Names, and then to go beyond that to the Bible Knowledgebase.
While we’ve got a lot of interesting data about characters in the Bible, there’s still not as much as i’d like: so how to prioritize additional development? Well, one practical answer is to assign a weight to each one, then start at the top and work your way down, and stop when it’s time to stop (typically because money, enthusiasm, or both are exhausted). While this isn’t a perfect approach to resource development, it’s a pretty good one, and pretty good is often good enough when you’re in new territory anyway.
Since we’ve got the data that maps people to the passages that refer to them, it’s pretty easy to go through and count. Note an important detail: i really do mean references to people, not just strings. It’s not enough to find the string “Judah” in a verse: you want to know when it’s Judah the person, as opposed to a cover term for Israel or the Southern Kingdom. For hard cases like Judah, the only way to know that is go through verse by verse and decide. For many other cases, while the string is only used to refer to people, there are numerous people with the same name. Zechariah is the Big Daddy here: there are 30 distinct ones in our database (this author found 31, but i haven’t gone through them to determine where the discrepancy lies). So just counting occurrences of “Zechariah” doesn’t get it right either: you have to count all 30 cases differently (for those who like skipping to the end of murder mysteries, the prophet Zechariah, whose prophecies are recorded in the book of the same name, gets mentioned the most). You also have to know which names refer to the same person: Simon is Peter is Cephas, and any instance of those names (that refers to Jesus’ disciple, as opposed to one of the other Simon’s) counts. So you need some real data to be able to do a reasonable job with this computation.
There are a lot of different ways you could count: here’s one. Let frequency be a count of the number of verses that mention a given individual (only counting one for verses like Luke 22:31, “Simon, Simon, Satan has desired to sift you like wheat”, which shouldn’t really count as two observations of Simon’s significance as a Biblical character). Let dispersion be the number of books of the Bible that mention the individual. The intuition here is that, for two individuals with the same frequency, the one that’s mentioned in more books is probably more important, broadly speaking. Normalize each of these by their maximum values (max frequency is 1370, max # of books is 31) just to scale things a little more nicely. Then assign a weight to each of these factors (i used 0.6 for frequency and 0.4 for dispersion) and combine them to get a number between 1 and 0.
Here’s what the graph looks like for the top 50 (there are a total of 2987 men and women), ranked by the composite metric (the green line) that combines frequency (the blue line) and dispersion (the red line). The image is linked to a larger version where you can actually read the names.
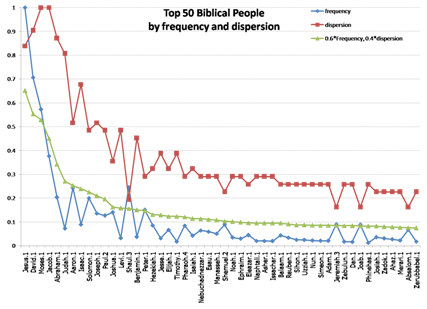
While the top names (Jesus, David, Moses, Jacob, Abraham) are no surprise, there are some interesting observations to make from this. First, the composite metric really does change the rankings: Levi is #14 by this method, but #53 if you only ranked by frequency. Likewise, Shaul (King Saul) would be #52 if you only ranked by distribution, because he’s mentioned in just a few books: but he’s clearly one of the most important characters in those books, and so it seems fitting that incorporating frequency boosts him up to #15 in the composite metric rank. You see graphically from where the the red and blue lines approach the cases where frequency and distribution are more equal, and places where they’re farthest apart (Judah’s a good example) where they’re most skewed. Back to the previous point about counting genuine person name instances versus strings: only 99 of the approximately 780 occurrences of “Judah” actually refer to Jacob and Leah’s son, so counting strings would be pretty misleading.
Since names, like many linguistic phenomena, typically follow a Zipfian Distribution (sometimes called a “long tail” or power law distribution), it’s no surprise that the majority (1634 of the 2987) of these names occur exactly once in the Bible, and the 59 most frequent names account for about half of all the name mentions in the Bible. So clearly these top names deserve much more attention than the long tail.
Important disclaimer: i’m not making any claims here about theological or historical importance. That’s a subjective matter, and you’d get different answers depending on your perspective. For example, John the Baptist doesn’t even make the top 50, but by Jesus’ own words in Luke 7:28 “among those born of women none is greater than John.” (ESV) So clearly his importance isn’t measured particularly well by this approach. But as a general approximation to how important different names are across the Bible, this isn’t a bad start. To be completely thorough, you’d also want to count pronoun (“she”) and descriptive (“the woman”) references: but we don’t have data for those yet.



